
Let’s be honest: the data center industry is currently obsessed with the gigawatt campus.
For the past year, the conversation has been dominated by the brute force reality of training large language models. We are building massive AI factories: core facilities defined by high density liquid cooled clusters, dedicated substations, and enormous capital expenditure. That centralized model is absolutely critical for the heavy lifting of model training, tuning, and orchestration.
But as AI moves from training into widespread production, the architectural challenge starts to shift. Power still matters, but the bigger question becomes where each workload actually needs to live.
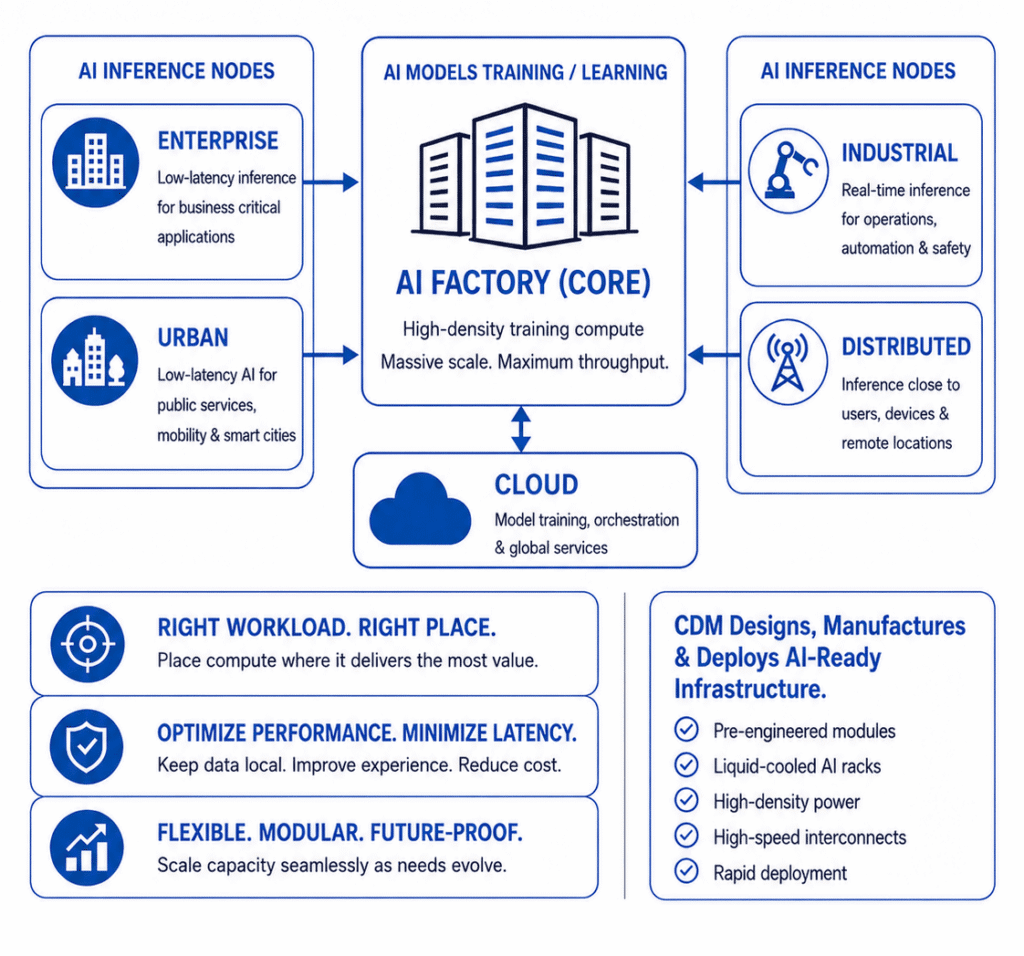
The Reality of Inference
Large scale AI training is often concentrated in core environments. Deploying AI into the real world is not. Once a model moves into production to perform inference, it runs into the hard physics of latency, bandwidth, and data gravity. You cannot route real time industrial robotics safety data back to a hyperscale cloud region hundreds of miles away and expect the same performance. You cannot rely on a centralized core to process every high frequency enterprise workflow without creating network, cost, and latency challenges.
Inference workloads demand geographical dispersion. While the specific use cases are virtually limitless, we are consistently seeing several common deployment models emerge outside the core:
- Industrial Nodes: Real time inference on the factory floor for automation, robotics, computer vision, and operational safety.
- Enterprise Nodes: Low latency AI capacity deployed directly on business campuses to support proprietary, mission critical applications while maintaining greater control over data and infrastructure.
- Urban and Public Sector Nodes: AI deployed closer to city environments to support mobility, public services, and smart infrastructure.
- Distributed Networks: Remote towers, telecom environments, and distributed sites bringing AI closer to end user devices and data sources.
None of these nodes replace the core AI factory. They are tethered to it. Models, updates, telemetry, and operational data flow continuously across a unified network fabric. But physically, the compute has to sit where it delivers the most value.
Why Modular Is the Most Practical Path Forward
This distributed reality creates a massive engineering challenge. You cannot simply drop a 100kW AI rack into a standard telco closet or a traditional low density colo and hope the building’s HVAC can handle it.
High density compute requires high density infrastructure wherever it lives. Whether it is a massive core facility or an enterprise inference node, the engineering disciplines remain the same: precision cooling, robust power delivery, power telemetry, physical security, high speed interconnects, controls, commissioning, and long term serviceability.
This is why the industry is moving toward modular, AI ready infrastructure. At Compu Dynamics Modular, we are seeing that true scalability is not just about building bigger. It is about deploying smarter.
Pre engineered modules allow architects and operators to deploy purpose built, AI ready capacity where the workload demands it, without the delays and complexity of traditional stick built construction. The goal is not to remove engineering from the equation. It is to capture the engineering in a repeatable, reliable deployment model.
That distinction matters. Modular AI infrastructure is not a shortcut. Done right, it is a disciplined way to standardize the parts that should be repeatable while still configuring the system around the workload, site, power, cooling, network, and operational requirements.
Design from the Workload Outward
AI strategy and infrastructure strategy are now the same conversation. If you design a brilliant AI application but deploy it on infrastructure located too far from the user, the application will struggle. If the latency budget, cooling capacity, network path, or power envelope does not match the workload, the architecture breaks down.
The next era of data center design requires us to look at the workload first. Determine the latency budget. Assess the data gravity. Understand the power and cooling requirements. Then deploy the right infrastructure, whether that is a core AI factory, a distributed inference node, or a connected architecture across both.
In the AI race, raw speed matters. But architectural placement is what wins the marathon.
